非参数方法最近已成功应用于语言建模和问答系统。非参数的方法具有如下优势:
- 表达能力强,因为它们可以在测试时使用任意数量的数据
- 适应能力强,因为预测可以通过改变数据存储来控制
- 可解释性强,因为用来进行预测的数据可以直接检查
1 信息
- 论文标题:Efficient Cluster-Based k-Nearset-Neighbor Machine Translation
- 公开源码: PCKMT
- 会议/期刊: ACL2022
- 论文单位: 天津大学,阿里巴巴达摩院
2 背景
基于 KNN 的检索式增强首先在Language Model上被提出,在 2021 的 ICLR 文章中,首先将 KNN 增强的方法应用到了机器翻译上, 通过 KNN 的词级别的检索和融合,能够在不进行特定领域训练的前提下,有效提高模型在领域数据集上的效果。其包含两个主要的步骤:首先是创建数据库(Datastore),也就是使用基础模型来进行正向传播,利用在解码时候映射到词表前的特征和对应的目标词作为键值对存储在 Datastore 中,对应图 1 中 Datastore 的 Representation 和 Target。
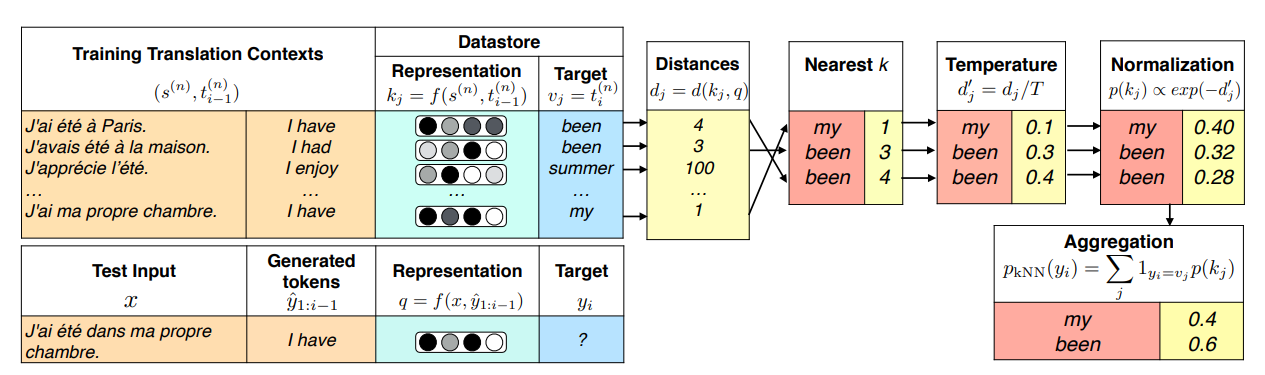
其次,在正式翻译时,每个具体的解码步骤中,使用相同位置的特征,从 Datastore 中进行向量检索,使用检索的结果以及对应的距离(Distances),结合温度超参数来计算得到最终的概率(对应公式 1):
$$P_{kNN}(y_i|x,\widehat{y}_{1:i-1})\propto \sum _{(k_j,v_j)\in \mathcal{N}}\mathbb{l} _{y_i=v_j}exp(\frac{-d(k_j,f(x,\widehat{y} _{1:i-1})}{T})$$
其中$\mathcal{N}$表示在Datastore中进行向量检索得到的$N$个键值对, $T$表示温度超参数,$\mathbb{l}_{y_i=v_j}$代表指示函数,表示只在对应满足条件的位置添加概率。
将得到的概率作为目标词概率按照一定比例融合到原始模型输出词表的概率分布上(对应公式 2):
$$p({ y_i|x,\widehat{y} _{1:i-1} = \lambda p _{kNN}(y _i|x,\widehat{y} _{1:i-1})+(1-\lambda)pMT(y _i|x,\widehat{y} _{1:i-1}) }$$
其中$\lambda$是比例超参数,$p_{kNN}$是上面介绍的kNN检索过程计算得到的对应概率,也就是对应公式1,$pMT$表示基础模型得到的词表上的概率分布。
3 任务
检索式增强在各种自然语言处理任务中被广泛应用,其主要目的是基于一定的检索范式来利用现存数据,影响模型最终得到的结果,从而降低模型参数的负担。本文是在机器翻译任务中利用检索来进行增强的最新范式。
4 问题
虽然2021的ICLR 文章在实验部分进行了不同领域的实验,并且得到了良好的效果,展现出来了KNN无参数机器翻译在实际应用上的前景,但是在实际应用中存在两个主要的问题:
- 存储大小: 对于KNN无参数机器翻译而言,在创建 Datastore 的时候,使用词以及对应的特征来作为存储的键值对,最终的 Datastore 的大小跟词的数量以及特征的维度是正相关的。
- 时间延迟: 因为 KNN 的向量检索是在每个解码步骤中进行的,随着 Datastore 的增大,向量检索的延迟会严重影响最终整体翻译的速度。
5 方案
ACL 2022这篇论文中,作者首先给出了一个在领域数据集上原始的机器翻译和KNN机器翻译的速度对比,其中MT表示的是原始机器翻译模型,AK-MT是KNN-MT的一个变种,也是该论文的Base模型。上述的两个主要的问题都与 Datastore 的大小有着密切的关系,作者基于对特征的可视化分析,提出了两个不同方向改进:
- 1. 特征维度: 使用一个额外的网络(Compact Network)来对模型的特征进行降维。并且基于不同的语义单元应该互相不重合的假设下,使用对比学习的方法来在降维的同时对不同的语义单元进行分割,增强向量检索的准确度。
- 2. 词数量: 使用一个剪枝策略来对Datastore中冗余的部分进行修剪从而降低Datastore的大小,进一步提升翻译的速度。

6 新意
6.1 基于聚类的特征维度压缩
在KNN机器翻译研究中使用的原始模型的特征维度通常为1024维,并且在通用的数据上训练得到的模型。因此模型是缺少领域相关知识,并且高维语义空间下,向量是稀疏的并且带有噪声。使用传统的降维方法(比如 PCA),在相关研究中中被证明效果比较差,对于 1024 维而言,在保证性能的前提下,最多只能够降低到 512 维。
在这个部分,基于不同的语义单元以及对比学习的方法,作者不仅对特征维度进行进一步的压缩(1024维—64维),而且进一步提升了领域数据集上的性能。具体主要分为两个步骤:

- 1.形成基础的语义单元
在这里引入了一个概念——Cluster Family。其表示的就是在 Datastore 中所有相同的目标词的键值对集合。对于一个 Cluster Family,使用传统的聚类方法来形成若干个簇(Cluster),使用得到的簇来作为最终的语义单元,体现在图3中的就是 Token A 和 Token B 分别形成了两个不同的簇,也就是得到四个基础语义单元。从图3中也可以看到,不同的簇之间可能是会存在重叠的部分,因此就需要下面的第二个步骤。
- 2.对比训练
不同的语义单元应该是互相不重合,因为重合会导致在检索时候的不准确问题,从而影响最终的翻译性能。具体的,在这里使用了两种不同模式的对比学习loss,来对压缩后的特征进行训练。分别为:Triplet Noise-Contrastive Estimation (NCE) 和 Trplet Distance Ranking(DR),其中前者是使用一个额外的线性层来转成了一个分类任务,而后者是直接使用压缩后的特征来计算L2距离进行排序。
在对比学习的训练中,锚点和正例是从同一个簇中获得,而负例是从不同目标词的簇中获得。另外还有一个额外的 Word Prediction Loss(WP),是为了将语言学的信息融入到训练压缩特征的网络中。
从图3中可以看到,Compact Network 主要分为两个部分,也分别对应两个不同的作用,其中$f(\alpha)$是特征压缩层,用来对特征的维度进行压缩。 $f(\theta)$是对比学习层,用来适应NCE的训练需要。特别的,训练NCE 的$f(\theta)$的输出维度是 1,训练 WP 的$f(\theta)$的输出维度是目标语言的词表大小,训练 DR 的时候不需要$f(\theta)$ ,因为它是直接对压缩后的特征进行操作。
6.2 基于聚类的数据库剪枝
除了特征以外,词的数量是另一个影响 Datastore 大小,进而影响最终翻译速度的重要因素。针对 KNN 的具体过程,一个直观的动机就是:在具有相同目标词的情况下,如果对应特征之间的区分度足够小,那么是可以视为冗余部分并且进行删除的。作者从统计机器翻译中短语级别的剪枝策略更有效这一结果得到启发,设计了一种基于 N-Gram 的剪枝策略。
首先定义了一个具体的衡量标准——**翻译代价(Translation Cost)**。具体的,针对某一个目标词,其翻译代价就是在这个目标词的来源语料中,以这个目标词作为结束词的 N-Gram 的困惑度,为了更好衡量翻译代价,使用 1 到 N 的 N-Gram 中的最低困惑度作为最终的翻译代价。

如图 4 中,对于 Datastore 中的目标词”man”来说,第一句和第二句得到的键值对相对而言就是冗余。在得到 Datastore 中所有目标词的翻译代价以后,在目标词的内部根据翻译代价来进行聚类,并且在剪枝的时候对所有得到的簇根据预设的比例进行随机采样,最终得到剪枝以后的 Datastore。
7 价值
论文中使用了 5 个不同的领域数据集分别为 IT、Koran、Medical、Law 和 Subtitles。其中前四个数据集是 Baseline 论文中使用的数据集,后者是包含了更多的数据用以表现剪枝的性能。对于特征维度也就是 的输出大小,实验中使用 IT 数据集在 [16, 32, 64, 128] 中进行搜索,并且最终确定为 64。剪枝策略中的 N-Gram 中的 1-N 设置为 1-2。
8 效果
8.1 特征维度压缩性能
首先对论文中提出的不同损失和锚点选择方法进行了组合,在 IT 数据集上进行实验。其中 DY 代表随机选择簇中一个点,ST 表示选择簇中心作为固定的锚点。CL 代表在不同的 Cluster 间选择负例进行对比学习的训练,而不是把负例的选择约束在不同 Cluster Family 上的簇中。
值得注意的是,传统的降维方法(PCA & SVD)在性能上都有所降低。在三个 Loss 中,NCE 的效果表现最好,可能的原因是 NCE 的参数相较于 WP 来说更少,在使用少量验证集训练的情况下,能够得到更好的结果。而 DR 性能差在于本身得到的特征已经是训练好模型上的结果,最小化距离的约束可能过于强硬。

在不同数据集上的实验结果如图 6 所示,基本的设置跟图 5 中最优设置一致。在不同数据集上均能够得到更好效果。并且为了测试训练的 Compact Network 的泛化能力,作者使用了一个大规模的通用语料库 Wikimatrix Corpus 来训练 Compact Network,然后直接在四个数据集上进行测试,可以看到在整体上得到的结果依旧是较好的。

对于 Compact Network 降维后的特征进行可视化,结果如图 7 所示,随机选择 10 个目标词来可视化,左边是原始的特征,右边是降维以后的特征。可以看到右边不同点之间的聚类效应更加的明显,证明了对比学习在降维的时候确实起到了将不同簇分割的效果,验证了所提方法的有效性。

8.2 剪枝策略性能
在这个部分进行的是剪枝方法的实验,图 8 中给出了其他四种不同的简单剪枝方法和本文提出的方法在四个领域数据集上的效果。其中 SP 表示根据与聚类中心的距离来进行剪枝,LTP 和 HTP 分别代表对翻译中生成概率低和高的部分进行剪枝,RP 表示使用随机均匀采样的方法来进行剪枝。

从结果上看,本文提出的方法在总体上是优于其他方法的,但是效果的提升比较有限,反而是随机的方法依旧保持可比性。根据统计的 N-Gram 可以看到,出现这种情况的原因可能在于构成 Datastore 的数据集中的 N-Gram 的冗余度是很低的,大部分 N-Gram 都是独一无二的。
所以要体现剪枝算法的性能,需要一个更大的数据集来实验。在这里作者使用了 Subtitles 数据集来进行实验, 并且跟 RP 来进行对比,在 Subtitle 这个比较大的数据集上结果如图 9,剪枝能够起到更好的效果,并且相较于 RP 而言,本文提出的方法随着剪枝比例提高,效果更加稳定。

最后就是剪枝以后的速度和效果对比(图 10),在 Subtitles 数据集上能够进行更大比例的剪枝,并且模型性能得到了一定提升,证明了剪枝方法的有效性。从最终结果上,我们也可以看到,特征维度压缩和剪枝都能够起到提升翻译速度的作用。

9 结论
该论文针对 KNN 无参数机器翻译中需要较大的存储空间和速度慢的两个主要问题,在创建的 Datastore 中引入语义单元的概念,并且基于不同语义单元不重合的假设,在特征维度进行压缩的时候使用对比学习来进行训练,在保证性能的前提下将特征维度从 1024 维降低到了 64 维,缓解了要求较大存储空间的问题。并且提出了基于 N-Gram 的剪枝策略,在大规模数据集上体现出来了较好的效果。两个方法都能够降低 KNN 所带来的额外时间损耗。实验表明,降维以后的特征中不同语义单元的聚集现象更加明显,并且在所有数据集上都能够取得 SOTA 的效果。



